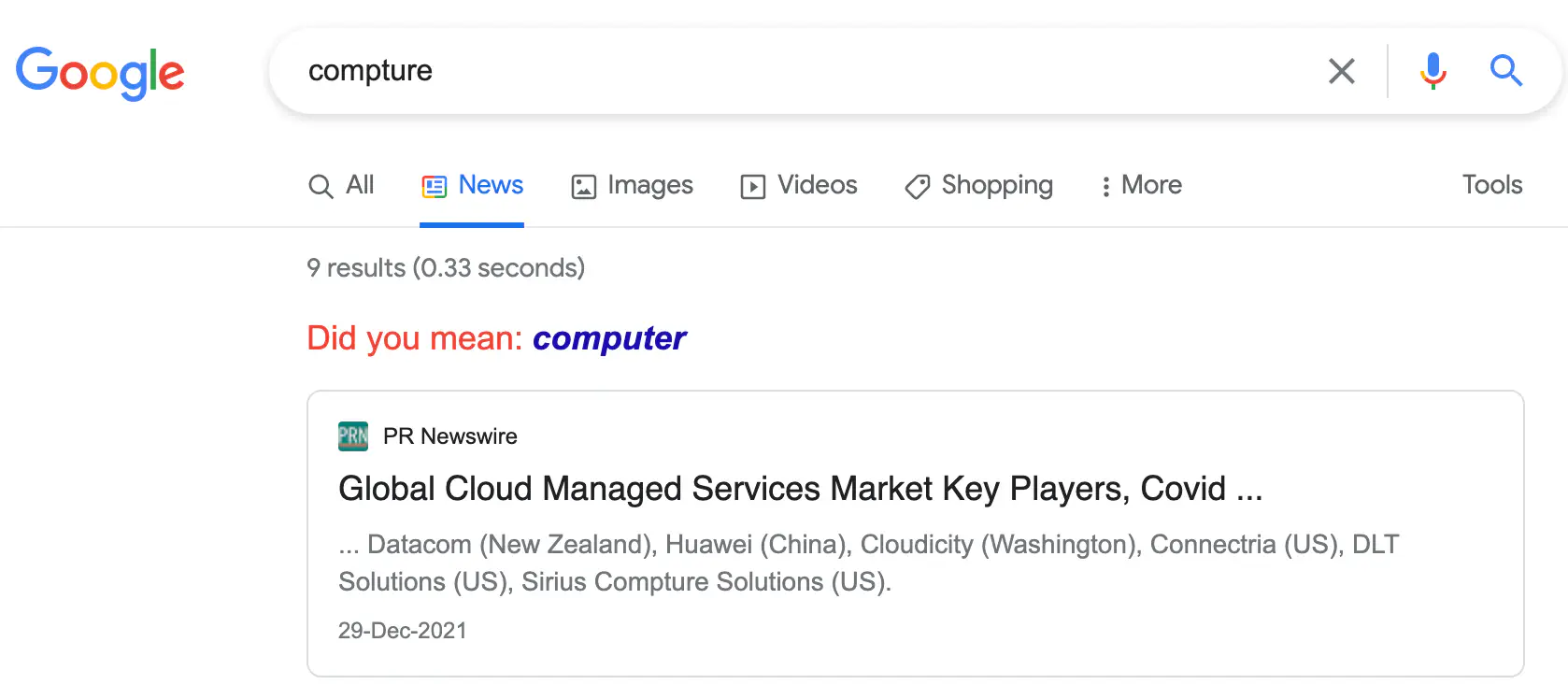
In this blog post, we will create in Lucene Did you mean feature as seen in Google. Let’s begin by understanding what this feature is.
Whenever you misspell a word in google, google is able to figure out that you made a mistake. If the mistake is not significant, then google simply shows results for what it thinks is the correct spelling. It also gives you the option to search instead for the original query you entered.
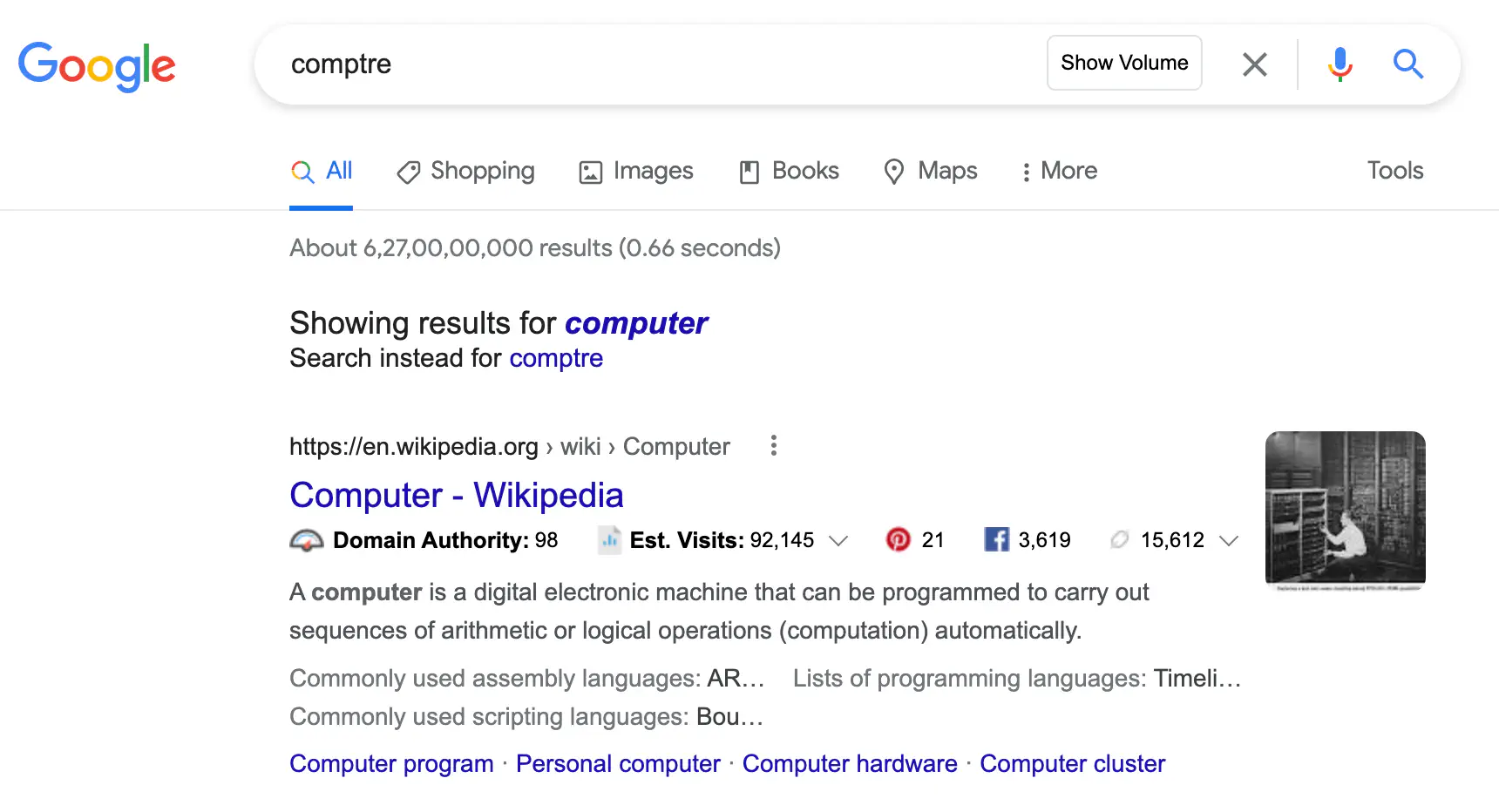 But if it feels there is a significant difference in the spelling of the query and what it thinks the right query is, it will ask you what you meant by using the “Did you mean” feature as shown below:
But if it feels there is a significant difference in the spelling of the query and what it thinks the right query is, it will ask you what you meant by using the “Did you mean” feature as shown below:
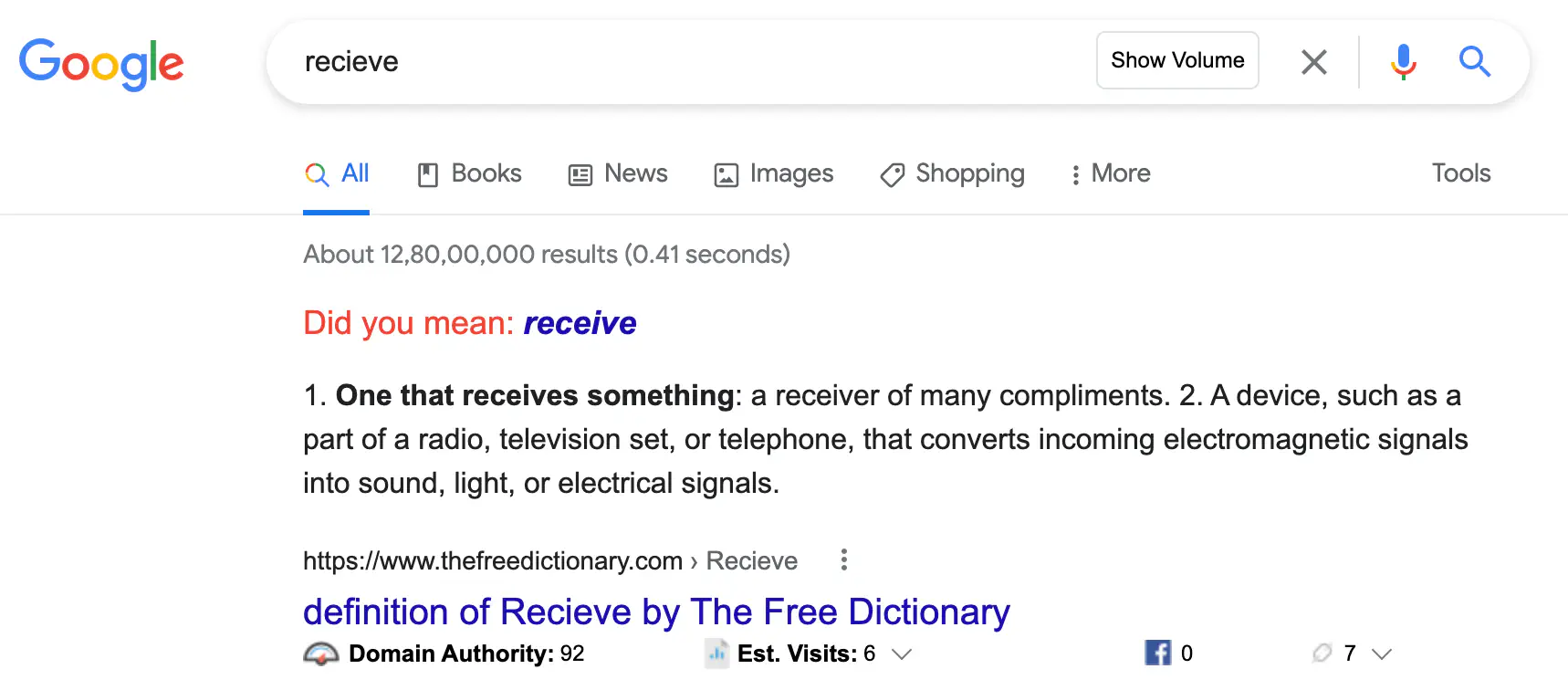
Lucene did you mean feature java example
If you are creating a search engine using Apache Lucene, you can create a similar feature.
We can create in Lucene DID YOU MEAN feature by using the Hunspell dictionaries. These come prebuilt in Lucene in the analyzer common library.
To create a Did you mean feature in Lucene we need to have the following capabilities:
- We need to know when a word is not spelled correctly. This will help us show the did you mean prompt to the user only when we need to.
- Once we know the word is misspelled, then we need the ability to show the correct spelling.
We can achieve both these things using Lucene’s Hunspell class. Here is a working example of how to use the Hunspell class.
Dependencies
We need Lucene’s core and analyzers-common library.
In case you are using MAVEN, copy the following dependencies in pom.xml
1<dependency>
2 <groupId>org.apache.lucene</groupId>
3 <artifactId>lucene-core</artifactId>
4 <version>8.10.1</version>
5</dependency>
6
7<dependency>
8 <groupId>org.apache.lucene</groupId>
9 <artifactId>lucene-analyzers-common</artifactId>
10 <version>8.10.1</version>
11</dependency>
Hunspell Dictionary files
For this feature to work you need the following two libraries:
You can get affix and dictionary files for other languages here.
JAVA code
Here is the java code. It does two things:
- Check the spelling of words and
- Get some suggestions for words.
1package upmanyu.ishan.lucene.tutorial;
2
3import org.apache.lucene.analysis.hunspell.Dictionary;
4import org.apache.lucene.analysis.hunspell.Hunspell;
5import org.apache.lucene.store.Directory;
6import org.apache.lucene.store.FSDirectory;
7
8import java.io.*;
9import java.net.URL;
10import java.nio.file.Files;
11import java.text.ParseException;
12
13public class DidYouMean {
14 public static void main(String[] args) throws IOException, ParseException {
15 Directory directory = FSDirectory.open(Files.createTempDirectory("temp"));
16 InputStream affFileStream = new FileInputStream("src/main/resources/hunspell/en-US/en_US.aff");
17
18 InputStream dicFileStream = new FileInputStream("src/main/resources/hunspell/en-US/en_US.dic");
19 Dictionary dictionary = new Dictionary(directory, "spellCheck", affFileStream, dicFileStream);
20
21 Hunspell spellChecker = new Hunspell(dictionary);
22
23 String correctWord = "guava";
24 String misspelledWord = "recieve";
25
26 System.out.println(String.format("Is %s spelled correctly?: %b", correctWord, spellChecker.spell(correctWord)));
27 System.out.println(String.format("Is %s spelled correctly?: %b", misspelledWord, spellChecker.spell(misspelledWord)));
28 System.out.println(String.format("Did you mean: %s", spellChecker.suggest(misspelledWord)));
29 }
30}
OUTPUT:
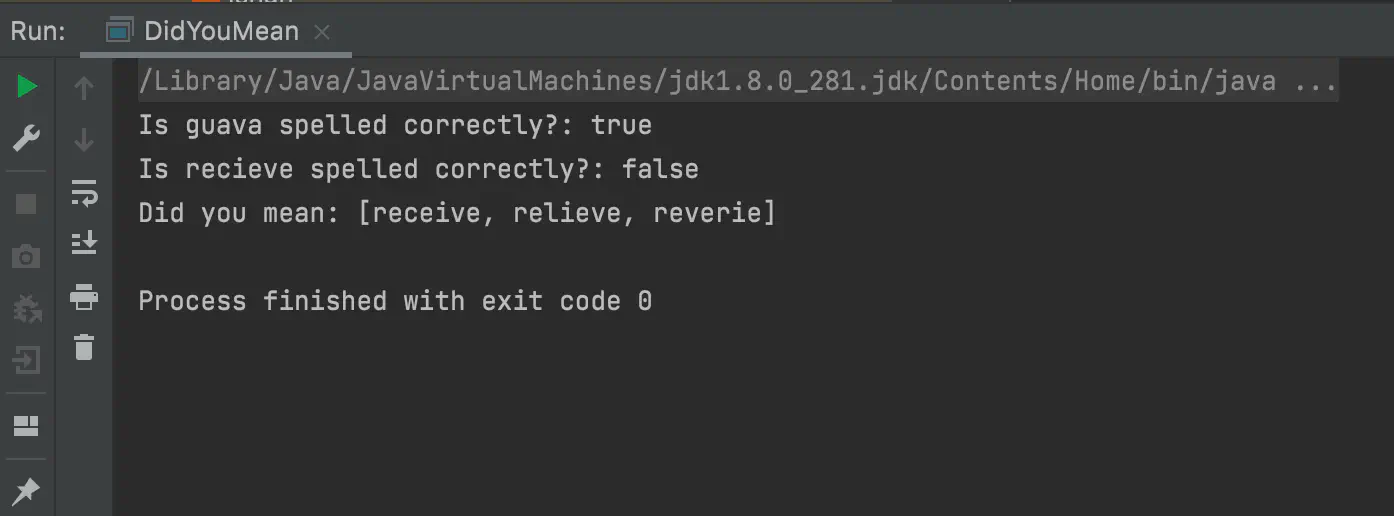
Now that you have seen the java code in action, let us try and understand how this code works. The core part of this code is the Hunspell class in Lucene. According to Wikipedia:
Hunspell is a spell checker and morphological analyser designed for languages with rich morphology and complex word compounding and character encoding, originally designed for the Hungarian language.
Hunspell is used by LibreOffice office suite, free browsers, like Mozilla Firefox and Google Chrome, and other tools and OSes, like Linux distributions and macOS. It is also a command-line tool for Linux, Unix-like, and other OSes.
How do Hunspell dictionaries work?
A Hunspell dictionary needs two files to work:
- Affix File: An affix file (*.aff) contains a list of suffixes and prefixes and rules describing them. The rules describe where we can use a suffix or prefix. For example, you may have a rule which says the suffix
iedcan be applied only if the last character of the word is y, in other cases suffixedshould be used. - Dictionary file: A dictionary file (*.dic) contains a list of words one per line. The first line of the dictionaries (except personal dictionaries) contains the approximate word count (for optimal hash memory size). Each word may optionally be followed by a slash (“/”) and one or more flags, which represents the word attributes, for example, affixes.
Using these two files, the algorithm tries to find if the word can be formed with the given affix and dictionary file rules.
As stated in Linux man-pages:
Consider the Dictionary file:
3
hello
try/B
work/AB
The flags B and A specify the attributes of these words.
http://manpages.ubuntu.com/manpages/bionic/man5/hunspell.5.html
and the Affix file:
SET UTF-8
TRY esianrtolcdugmphbyfvkwzESIANRTOLCDUGMPHBYFVKWZ'
REP 2
REP f ph
REP ph f
PFX A Y 1
PFX A 0 re .
SFX B Y 2
SFX B 0 ed [^y]
SFX B y ied y
In the affix file, prefix A and suffix B have been defined. Flag A defines a re-‘ prefix. Class B defines two -ed’ suffixes. First B suffix can be added to a word if the last character of the word isn’t y’. The second suffix can be added to the words terminated with an y’.
All accepted words with this dictionary and affix combination are: “hello”, “try”, “tried”, “work”, “worked”, “rework”, “reworked”.
http://manpages.ubuntu.com/manpages/bionic/man5/hunspell.5.html
Conclusion
In this blog post, we understood what did you mean feature in google is. Then we saw some code to create in Lucene Did you mean feature by using Hunspell dictionary. We ended this post by learning how Hunspell dictionaries work.
What Next?
If you enjoyed this article I am guessing you might be using Lucene to create a search application. I also created a search engine to search on English Wikipedia Articles. Do you want to know how I did it? Read all about it here.
References
- Linux MAN pages for Hunspell: http://manpages.ubuntu.com/manpages/bionic/man5/hunspell.5.html
- Hunspell Project on Github: https://github.com/hunspell/hunspell
- Hunspell Wikipedia page: https://en.wikipedia.org/wiki/Hunspell