You might have done a google search. Or you might have tried finding that favorite Ed Sheeran Video on Youtube. You may have tried finding the latest gadget you crave on Amazon. If your answer to any of the above questions was yes, you have already used an inverted index.
These websites work with millions and billions of web pages, songs, or products. Have you wondered how the results appear so fast? It happens because these websites have already built an inverted index of the information. When you search for something, instead of reading all the documents from starting to end, these sites lookup in an inverted index data structure.
What is an inverted index in information retrieval
An inverted index data structure allows you to find the information you are looking for in a fast and efficient manner. It does this by indexing the words contained in a document. But you must be wondering if we are simply indexing the document then why call it an “inverted” index?
Why is it called an “inverted” index?
In a normal structure, we have a document that contains words. So to find the word you read the complete document from beginning to end and stop when you find a word. But if our intent is to find if a document contains a word, we can do better.
Instead of storing documents to word mapping, an inverted index inverts this process. i.e it stores a mapping for words to document. We have a word that points to the list of documents that contains that word. So now if you want to find all documents that contain a word, we have that available as a list. In this way we have “inverted” the process and hence we call it an inverted index.
How to create an inverted index
Let’s dive deep and understand the structure of an inverted index data structure. But before we do that, let’s assume we want to add the following documents in our index:
- Document1: My name is Ishan Upamanyu
- Document2: Abhishek Upmanyu is a great comedian
- Document3: I would like to name my dog as Bruno
- Document4: Alexander the great.
- Document5: Abhishek is studying in Delhi.
Before we insert the words into our index, we need to do some pre-processing.
Preprocessing before creating the index
Tokenization
A document contains sentences. We need to break the sentences down into individual tokens. A token is the smallest unit that we can insert in our inverted index. We may split different words into different terms or we may split many words into a single token depending on our need. For eg: Consider the phrase: “I live in New Delhi”. We can break it into the following tokens:
- [I, live, in, New, Delhi]
or - [I, live, in, New Delhi]
The documents we have will be broken down into the following tokens:
- Document1: [My, name, is, Ishan, Upamanyu]
- Document2: [Abhishek, Upmanyu, is, a, great, comedian]
- Document3: [I, would, like, to, name, my, dog, as, Bruno]
- Document4: [Alexander, the, great.]
- Document5: [Abhishek, is, studying, in, Delhi.]
Once we have our individual tokens, we proceed to the next step.
Stop Words
We often have a lot of words like “a”, “and”, “the”, “is” etc that are used very frequently in language . These would not add much meaning to the search query. We can choose to remove these words from our tokens so that they are not added in the inverted index. These words that we want to remove are known as stop words. We may also want to remove punctuation in this step.
The output of this step would be:
- Document1: [My, name, Ishan, Upamanyu]
- Document2: [Abhishek, Upmanyu, great, comedian]
- Document3: [I, would, like, to, name, my, dog, as, Bruno]
- Document4: [Alexander, great]
- Document5: [Abhishek, studying, Delhi]
Stemming
We have a document containing the word “studying”. But suppose someone searches for the word “study”. Our index would not contain the queried word and we would fail to return a relevant document. So to solve this problem we convert the tokens to their root form. Stemming is the first way to do this. Stemming tries to remove the last few characters of the token to try and guess the right root word. For e.g, the words “care” and “caring” would be converted to the word “car” as stemming removed the last few correctors.
As you may have noticed, stemming might result in unexpected output. Like our searches for the word “car” would start to match with the documents containing the word “care”. This would happen because “care” is stemmed down to “car”. This is not what we want. We solve this problem with Lemmatization.
Lemmatization
Lemmatization converts the token to its meaningful base form. Like it would convert “caring” to “care” and not “car”. It does this by using dictionaries and doing a morphological analysis to reach the base form known as Lemma.
Some search systems also standardize the case of the token. They might convert all tokens to lower case. This has an advantage. Searches will start to match regardless of the case difference in document and query. For e.g. searching for “upmanyu” would match the document containing the word “Upmanyu”
After completing all the preprocessing, our tokens look as follows:
- Document1: [my, name, ishan, upmanyu]
- Document2: [abhishek, upmanyu, great, comedian]
- Document3: [i, would, like, to, name, my, dog, as, bruno]
- Document4: [alexander, great]
- Document5: [abhishek, study, delhi]
Building inverted index
Now that we have our pre-processing done, we can start building our inverted index data structure.
Step 1: First of all we create a table with a list of all the words and the document in which they occur.
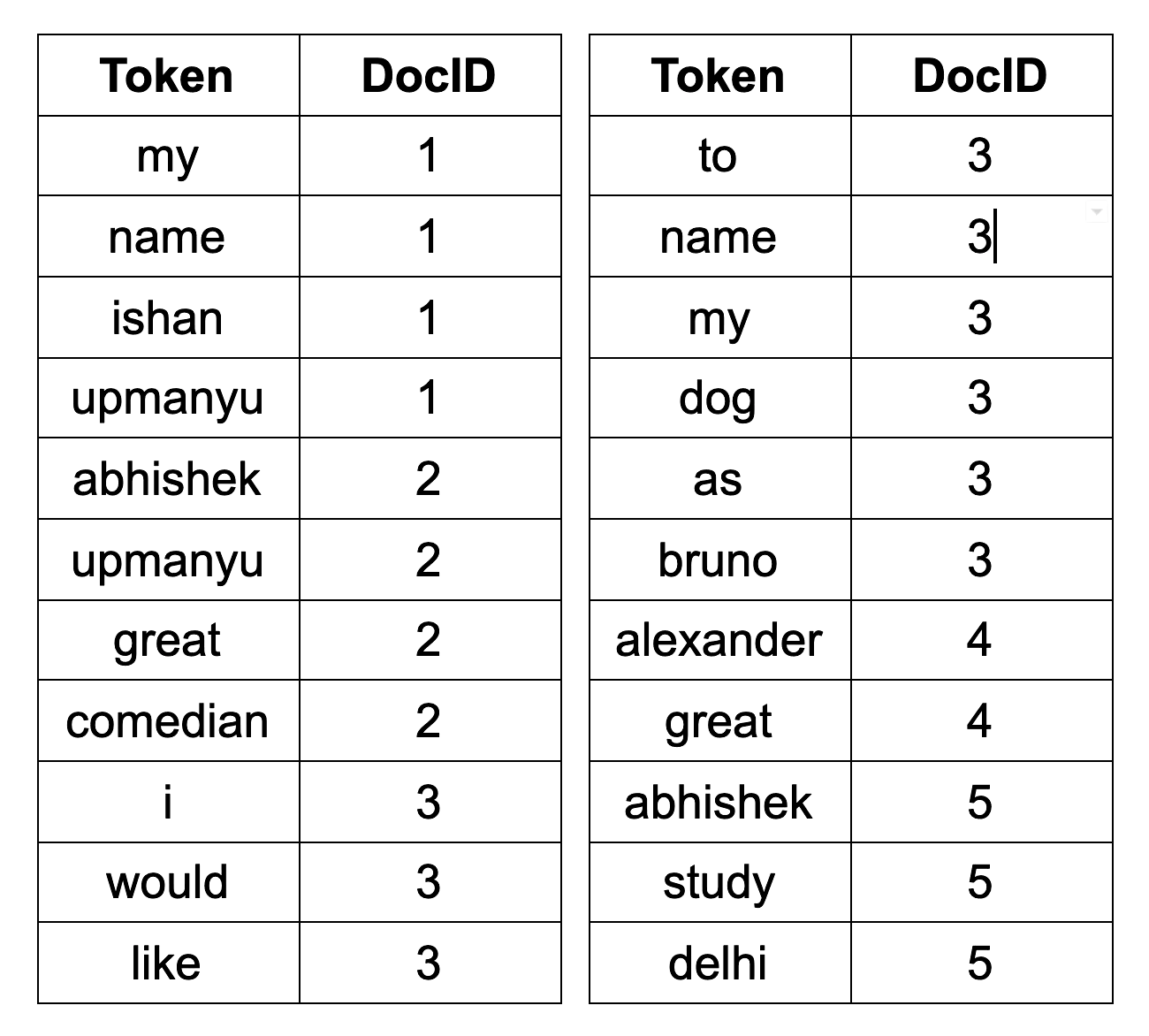
Step 2: Now we try to group words together sort them and note their frequency. Also, for the same word, we put the document id in a list and sort this list of document ids. The result now looks like this:
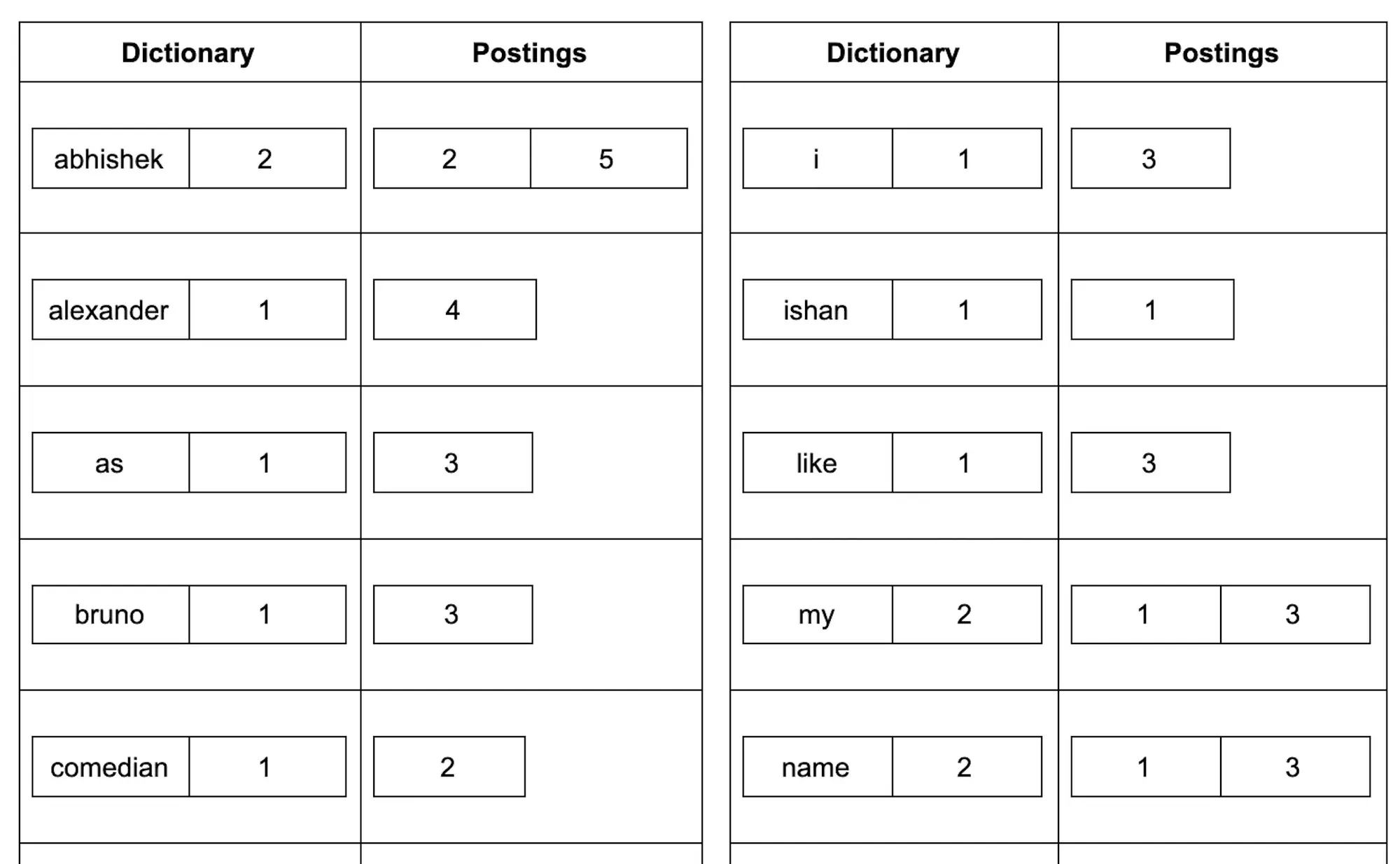
This is the structure of our inverted index data structure. As you can see, it has two main components:
- Dictionary
- Posting List
Dictionary and Postings
The part of the index which contains the word with its frequency is called a dictionary. It also stores a pointer to the list of documents containing that word. This list is called Postings. Each token stored in our dictionary is called a term. We can store the dictionary as an array or as a map depending on the implementation.
In array representation, we use binary search to find the token we are looking for. In a map implementation, we use hashing to find the token. We will soon see this in action when we see how we do retrieval, i.e. find documents matching our query using an inverted index data structure.
Token vs Term
A token is an output of splitting the sentence into smaller chunks. All these chunks will not become a part of our index. We may remove some of them or convert some of them to their root form as we saw in pre-processing step.
A term is an actual entry that gets added in the inverted index dictionary. It is what is actually present in the index.
How to use the inverted index to find what we are looking for
Now we know the internal structure of an inverted index data strucure. We also know how it is created. The next step is trying to understand how we can find the documents of interest in our inverted index data structure.
Let’s say we want to find all documents matching our search query.
Finding all documents that match a boolean query.
Boolean retrieval deals with queries combining multiple terms using Boolean operators. Boolean operators are AND, OR, NOT. For e.g. we may issue the following query: ishan AND upmanyu
With this query, we want to get the documents that contain both the search terms i.e. ishan and upmanyu
To process this we use the following steps:
- Search for ishan in the Dictionary.
- Locate its postings.
- Search for upmanyu in the Dictionary.
- Locate its postings.
- Intersect the two postings.
For our inverted index, the process looks as follows:
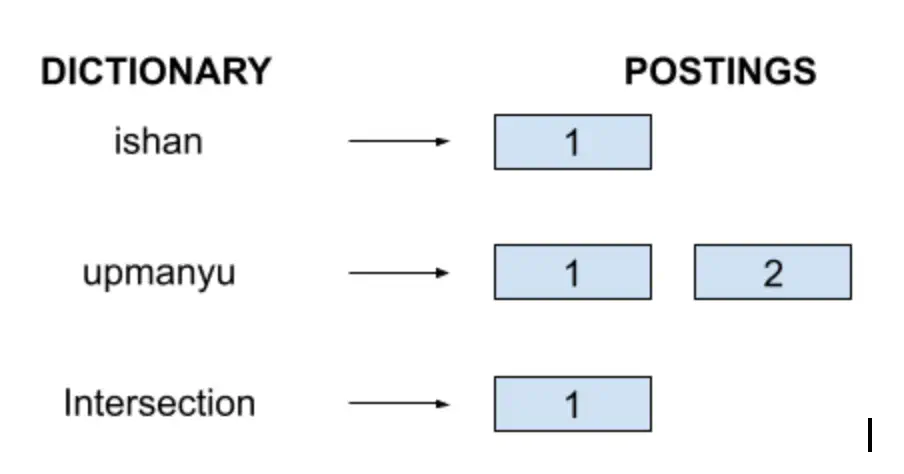
So for this query, we will return only Document1
Similarly, for the query ishan OR upmanyu we do the following steps:
- Search for ishan in the Dictionary.
- Locate its postings.
- Search for upmanyu in the Dictionary.
- Locate its postings.
- Take the union of the two postings.
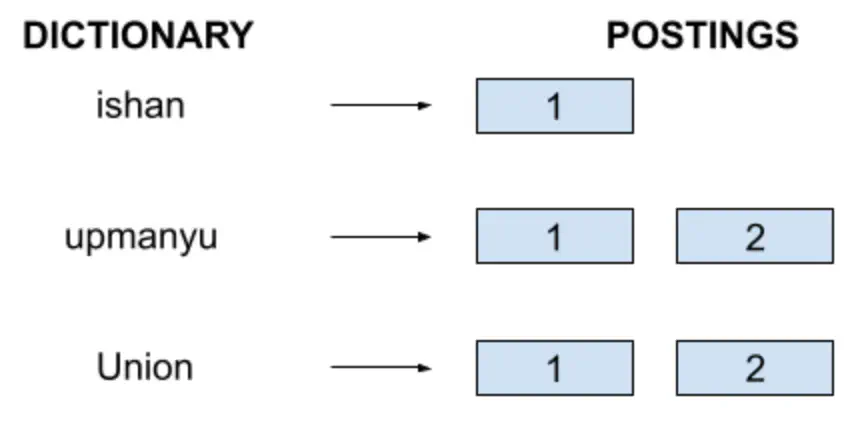
So for this query, we will return both Document1 and Document2.
EXERCISE: Try thinking about how NOT operator will be implemented and write your answer down in the comments.
Thus we conclude how to find something in an inverted index data structure.
Conclusion
In this article, we understood in detail what an inverted index data structure is. We understood the internal structure of the inverted index data structure. We also covered how the inverted index data structure is created and how it can be used to find the information we are looking for.
What next?
Now that you understand what an inverted index data structure is and how it works aren’t you curious that how is it used to rank results in a search engine? The answer is the vector space model of Information Retrieval. I recommend you read all about it here.
References
- A first take at building an inverted index: https://nlp.stanford.edu/IR-book/html/htmledition/a-first-take-at-building-an-inverted-index-1.html
- Boolean Retrieval: https://nlp.stanford.edu/IR-book/html/htmledition/boolean-retrieval-1.html
- Difference Between Stemming and Lemmatization: https://stackoverflow.com/questions/1787110/what-is-the-difference-between-lemmatization-vs-stemming#:~:text=Stemming just removes or stems,form%2C which is called Lemma.