
Apache Lucene is a popular information retrieval library written in JAVA. It helps you add full-text search capability to your application. This library is at the heart of search servers like Elasticsearch and Apache Solr.
It was created in 1999 by Doug Cutting, who also created Apache Hadoop, and is now a top-level Apache Project.
You can use Apache Lucene to create your own search application which can include features like term matching, phrase matching, fuzzy search, proximity search, and much more.
If you have been working with Elasticsearch or Apache Solr, then understanding Apache Lucene will help you to grasp how these technologies work.
To help you begin your learning journey, here are 7 concepts that will get you familiar with Apache Lucene.
Inverted Index – The reason Lucene is so fast
Lucene enables super-fast text search by using a special data structure known as the inverted index. Instead of having to look for text in sequential order in all the documents, Lucene pre-creates an inverted index of the documents.
You can imagine this inverted index to be similar to the glossary you find at the end of a book. The glossary at end of a book contains references to the page numbers where a word occurred. Similarly, the inverted index contains a mapping of terms and a list of documents containing that term.
For example, consider the following documents:
- Document1: My name is Ishan Upamanyu
- Document2: Abhishek Upmanyu is a great comedian
- Document3: I would like to name my dog as Bruno
- Document4: Alexander the great.
- Document5: Abhishek is studying in Delhi.
If these documents are indexed in an inverted index, the index will look like this:
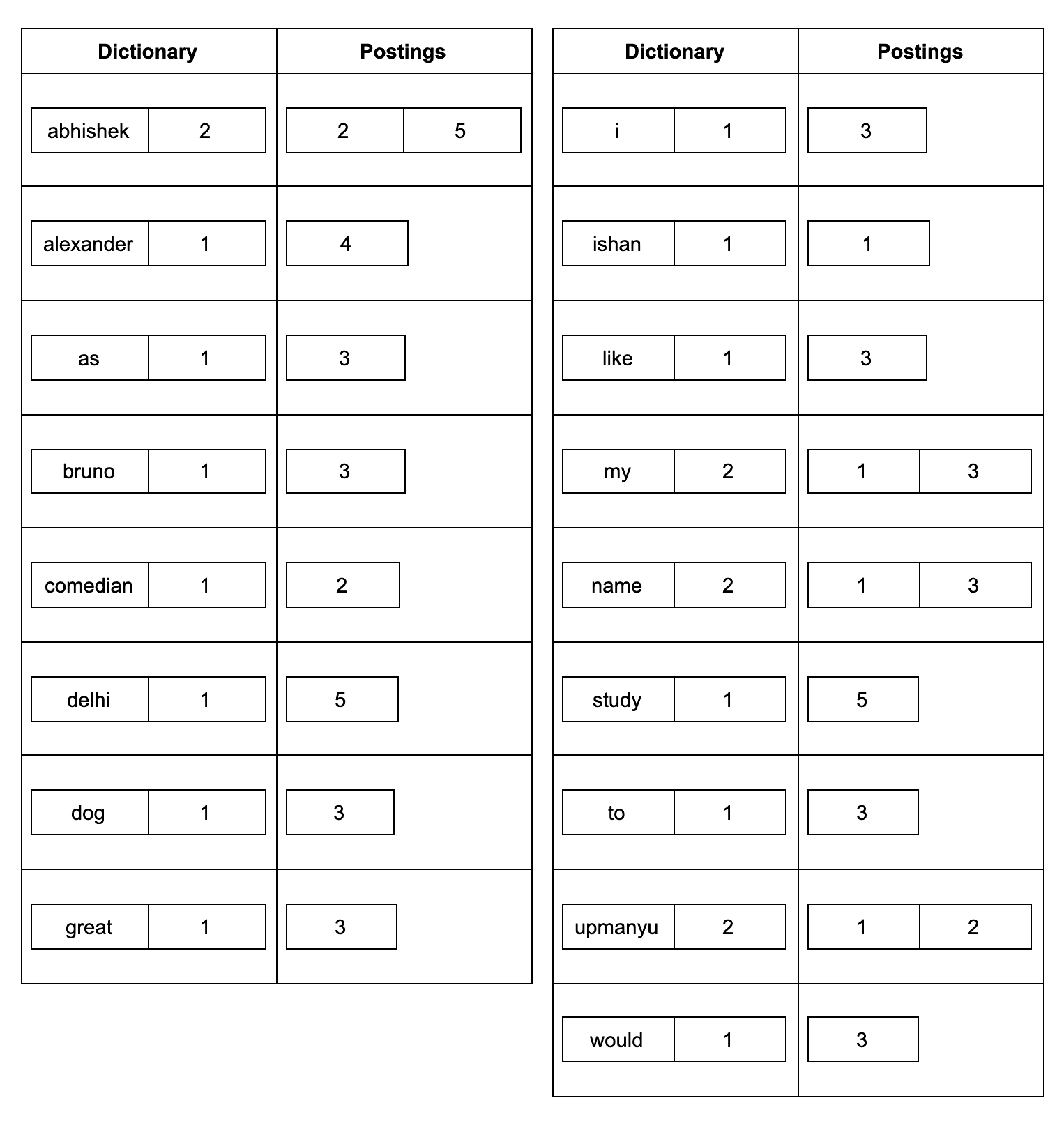
The inverted index has two components:
- Dictionary: This contains all the terms in the index along with their frequency
- Postings: This is the list of documents that contains the terms. In addition, the postings might also store information about where the word occurred in the document.
To understand how Lucene returns results using the inverted index, read the article on the inverted index here, followed by the article on how scoring works here.
Fields and Documents – The building blocks of your search system
When you start working with Apache Lucene, you will come across two terms: Field and Document. These are the ways in which you describe your data to Lucene.
Fields
Fields are the most basic unit in Apache Lucene. You can consider a field as a column. You can store information about your data using fields. For e.g. let us say you are indexing novels written by multiple authors. You can have separate fields for Author Name, Title of the Novel, the publishing date, and so on.
A field is made of 3 parts:
- Name: This is used to identify the field
- Type: This describes the various properties of the field. It is a subclass of IndexableFieldType
- Data: This is what the field holds. It can be a normal text, a number, or even a binary value.
To help you get started, Lucene has already created different types of fields. You can read about them in the field documentation.
Some of the available subclasses of Field are BinaryDocValuesField, BinaryPoint, DoubleDocValuesField, DoublePoint, DoubleRange, FeatureField, Field, FloatDocValuesField, FloatPoint, FloatRange, IntPoint, IntRange, LatLonDocValuesField, LatLonPoint, LongPoint, LongRange, NumericDocValuesField, SortedDocValuesField, SortedNumericDocValuesField, SortedSetDocValuesField, StoredField, StoredFieldsWriter.MergeVisitor, StringField, and TextField
IndexableFieldTypes – the properties of fields
There are a few details you need to know when working with Fields. Unless explicitly specified, Lucene will not keep the original text of the field. If you want that it should return the original text of the field that matched your query, then you need to tell this explicitly to Lucene by using and implementable of IndexableFieldType. The commonly used subtype of this interface is FieldType
The following methods of FieldType are noteworthypublic void setStored(boolean value): This method can be used to store the original text of the field.public void setTokenized(boolean value): If tokenized is set to true only then the field will be analyzed by the Analyzer. Don’t worry we will cover the analysis concept shortly.public void setIndexOptions(IndexOptions value): This method is used to control the information that should be stored in the inverted index. Check out the IndexOptions enum here.
Note that this can also be used to control advanced aspects like DocTypes and Term Vectors which are beyond the scope of this article.
You can check out other methods of FieldType class here.
Documents
A document is a collection of fields. You can consider it as a record in a database table. When you search for something, Lucene tries to find the document in which matching data is present. In our example when you indexed all novels, each novel record is a Document in Lucene.
So to index your data, you have to think about what fields each document will contain. You can describe this to Lucene using the following code:
To create a document use:
Document doc = new Document();
Now create a field. Here we will use an already created field class. The first constructor argument is the name of the field. The second argument is the content that we want to store. Ignore the last constructor argument, for now, you will understand this when we cover IndexableFieldType.
Field pathField = new StringField("path", file.toString(), Field.Store.YES);
Once you have a field, you need to add it to the document.
doc.add(pathField);
Analyzer – Preprocessing for indexed data and search queries
What is Analysis?
We know that Lucene stores data in an inverted index. Remember that inverted index stores terms in its dictionary. But what we give to Lucene is plain text. So how does Lucene convert this text to terms of the inverted index? This is done by a process known as Analysis. The analysis is done both at indexing time for the fields of the document that is indexed, and also at the Query time for the query so that Lucene can find the terms it needs to look up in the inverted index.
NOTE: Lucene does not care about parsing your documents. Your document can be in any format be it PDF, DOC, EXCEL, etc. But Lucene does not understand these formats. Before you can index this data, you need to convert this into plain text format. This process is known as parsing. Lucene does not handle parsing. Parsing the data is the format of the application using Lucene.
Tokenization
The process of converting the text into smaller chunks ( known as Tokens) for adding in the inverted index is known as Tokenization. This can include various steps like removing extra spaces, removing stop words, converting the words to the root stems, lowercasing the tokens, etc. Some of these steps are done before converting the text to tokens, in which case these are PreTokenization steps. Others are done after we convert them to smaller tokens, in which case they are known as PostTokenization steps.
Pre-tokenization analysis can include, among other things, removing HTML markup, and converting or removing text matching arbitrary patterns or sets of fixed strings.
Many post-tokenization steps can also be done, including (but not limited to):
- Stemming – Replacing words with their stems. For instance with English stemming “bikes” is replaced with “bike”; now query “bike” can find both documents containing “bike” and those containing “bikes”.
- Stop Words Filtering – Common words like “the”, “and” and “a” rarely add any value to a search. Removing them shrinks the index size and increases performance. It may also reduce some “noise” and actually improve search quality.
- Text Normalization – Stripping accents and other character markings can make for better searching.
- Synonym Expansion – Adding in synonyms at the same token position as the current word can mean better matching when users search with words in the synonym set.
Analyzer components
The analyzer performs its job, by chaining multiple components together. These components are as follows:
CharFilter
A char filter is used to perform PreTokenization steps like removing extra spaces or stripping HTML or any other conversion that you want to do to your text before converting it into tokens. Lucene provides some inbuilt CharFilter implementations like CJKWidthCharFilter, HTMLStripCharFilter, MappingCharFilter, and PatternReplaceCharFilter.
Tokenizer
A Tokenizer is what converts the text into individual tokens. It is a subclass of TokenStream. You can think of TokenStream as something which will help you get your tokens. In many cases, where CharFilter is not used, the Tokenizer is the first step of the analysis process.
TokenFilter
A TokenFilter is also a subclass of TokenStream. It is used to modify the tokens that are generated by the Tokenizer. Some common operations performed by a TokenFilter are deletion, stemming, synonym injection, and case folding.
Commonly used Lucene Analyzers
Here are some Analyzers that come built-in in Apache Lucene
WhitespaceAnalyzer: This breaks the text on WhiteSpaces. The logic for what is considered whitespace can be found here. This does not perform any case change.
StopAnalyzer: This analyzer can help you to remove stop words from the text. It breaks the text using LetterTokenizer which divides text at non-letters. Further, it lowercases the token using LowerCaseFilter and removes stop word provided using StopFilter
StandardAnalyzer: This analyzer tries to identify word boundaries as it uses StandardTokenizer. StandardTokenizer implements the Word Break rules from the Unicode Text Segmentation algorithm, as specified in Unicode Standard Annex #29. It further uses LowerCaseFilter to convert tokens to lower case and removes stop words using StopFilter
There are many more analyzers that are already created by Lucene. They are part of the analyzers-common API.
Exploring the Lucene API
Now that we know the basic concepts about Lucene, we are ready to write the code. In this section, we will explore few concepts that are related to the Lucene API.
IndexWriter – Writing data to Lucene indexes
IndexWriter is the main class that is used to create an index in Lucene. It is used to add documents to the index. To create an IndexWriter, we need two components: a Directory and a IndexWriterConfig. Further, IndexWriterConfig is used to specify the analyzer that we want to use. Let’s use StandardAnalyzer for our example.
Here is a sample code. Here we create Document with a single Field. We want to return the complete value of this field when we return the results. So we create a stored field.
1Analyzer analyzer = new StandardAnalyzer();
2
3Path indexPath = Files.createTempDirectory("tempIndex");
4Directory directory = FSDirectory.open(indexPath)
5IndexWriterConfig config = new IndexWriterConfig(analyzer);
6IndexWriter iwriter = new IndexWriter(directory, config);
7Document doc = new Document();
8String text = "This is the text to be indexed.";
9doc.add(new Field("description", text, TextField.TYPE_STORED));
10iwriter.addDocument(doc);
11iwriter.close();
QueryParser – Make Lucene understand what you want to search
Now that we have a document indexed, we will want to search it. But before we can do that, we need to make Lucene understand our query. This is done by QueryParser.
Let’s consider an example. Consider the simple query: “path“. This is a simple term query. This will try searching for the string “path” in the default field specified while creating the query. Lucene also supports searching by specifying a field explicitly. To do this you can issue a query in the format: <fieldName>:<query term>. eg: description: text. This will search for string “text” only in the description field. There are many other ways you can issue a query. The details of the Lucene query format can be seen here.
The job of QueryParser is to understand this query and construct the Query class that will be needed to actually run this query. You can use the query parser as:
1QueryParser parser = new QueryParser("description", analyzer);
2Query query = parser.parse("text");
Note: In this example since we have not specified any field, it will search in the default field “description” only.
IndexSearcher – Searching for documents in your index
Once you have a Query, you can use IndexSearcher to run the query. This is the class that actually runs the query against the Lucene indexes and it gives you results in a TopDocs object. This object contains the documents that matched your query in form of an array of ScoreDoc objects.
1DirectoryReader ireader = DirectoryReader.open(directory);
2IndexSearcher isearcher = new IndexSearcher(ireader);
3ScoreDoc[] hits = isearcher.search(query, 10).scoreDocs;
The IndexSearcher needs a DirectoryReader. This should point to the same directory where you created the index.
To bring it all together, now our code looks like this:
1 Analyzer analyzer = new StandardAnalyzer();
2
3Path indexPath = Files.createTempDirectory("tempIndex");
4Directory directory = FSDirectory.open(indexPath)
5IndexWriterConfig config = new IndexWriterConfig(analyzer);
6IndexWriter iwriter = new IndexWriter(directory, config);
7Document doc = new Document();
8String text = "This is the text to be indexed.";
9doc.add(new Field("description", text, TextField.TYPE_STORED));
10iwriter.addDocument(doc);
11iwriter.close();
12
13
14// Parse a simple query that searches for "text":
15QueryParser parser = new QueryParser("description", analyzer);
16Query query = parser.parse("text");
17
18// Now search the index:
19DirectoryReader ireader = DirectoryReader.open(directory);
20IndexSearcher isearcher = new IndexSearcher(ireader);
21
22ScoreDoc[] hits = isearcher.search(query, 10).scoreDocs;
23assertEquals(1, hits.length);
24
25// Iterate through the results:
26for (int i = 0; i < hits.length; i++) {
27 Document hitDoc = isearcher.doc(hits[i].doc);
28 assertEquals("This is the text to be indexed.", hitDoc.get("fieldname"));
29}
30ireader.close();
31directory.close();
32IOUtils.rm(indexPath);
These were all the concepts that you needed to know to get started using Apache Lucene. You are now ready to start using Apache Lucene. If you want a fully functional java code example, try running a demo as explained here. Now go get your hands dirty and write some code!